It’s confusing when we should use useMemo and when we shouldn’t.
useMemo isn’t free $
useMemo comes with a small cost. So we should understand when it’s a benefit, and when it doesn’t provide any value.
Small usage in RAM to memoize & remember the resulting value
It costs a small cpu cycle to loop over & compare the dependency array & run internal fn of useMemo
So we should be smart when we use it.
useMemo isn’t always needed
useMemo isn’t needed in certain cases. For example, casting something to Boolean, or doing simple math isn’t an expensive operation and returns a primitive like “boolean” or “number”. These value will always be the same every time they are re-render run
true === true and 5 === 5.
Conversely, an array or object don’t have equality,
[] !== [] and {} !== {} and new Date !== new Date.
Two tests of if you need useMemo
Is the calculation to get the value is complex (looping, calculating, initializing a class)?
Or is it cheap (comparisons of numbers, boolean, casting types, simple math)
Is the returning complex value (object, array, fn, or class)?
Or is it a primitive value that is simple to compare (number, boolean, string, null, undefined)
Examples
const date = useMemo(() => Date.parse(isoDateString), [isoDateString]);
I’m so glad you asked! The principles are similar. In general, all callback functions should be memoized via useCallback. Functions are considered a non-primitive value thus never have equality unless we memoize them via useCallback.
As a rule of thumb: Naming booleans in the affirmative
One of the most challenging aspects of software development is choosing the good names for variables. This is particularly true when it comes to Boolean variables.
“Naming things is hard.”
– Some Software Developer
Affirmative names are those that start with words like is, has, or can which clearly indicate that the variable is a Boolean.
Affermative Booleans Variables
Our goal is to be consistent in the naming & to keep it readable — almost like a sentence. Take a look at these examples, “Is logged in” or “has favorites” and “has no favorites”.
Affermative
Negative
isLoggedIn
!isLoggedIn
isEmpty
!isEmpty
hasFavorites
!hasFavorites
canEdit
!canEdit
Great Boolean Variable Names
Reading these like a sentence is natural. “Is logged in” or “can not edit”. There is only one nation flip in your mind you must do when reading the negative cases.
Negative Booleans Variables
Now, let’s consider what happens when we deviate from the Affirmative Approach and use negative names.
Affermative?
Negative?
notLoggedIn
!notLoggedIn
isNotEmpty
!isNotEmpty
hasNoFavorites
!hasNoFavorites
canNotEdit
!canNotEdit
Confusing Boolean Variable Names
Our negative cases create a double negative! 😯
Try to read that negative statement as a sentence. “Does not have no favorites?” I think I know what that means, but that feels like an awkward way of saying “hasFavorites”.
The problem with negative named booleans is that they introduce the potential for double negatives. The Affirmative Booleans approach is more straightforward to mentally parse.
Conclusion
In general, naming Booleans in the affirmative is a practice that can significantly improve code understandability and maintainability.
Avoid no, and not, and other words that create the possible of a double negative when the boolean is flipped.
Naming things is hard, but naming boolean variables in the affirmative is a simple, yet effective way to help improve your code readability. Your future self and your teammates will thank you for it.
If you like thinking about naming, you may also enjoy thinking about pagination naming.
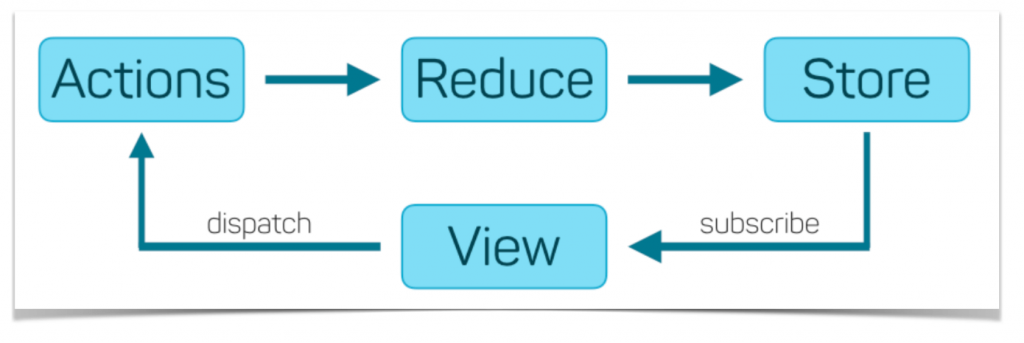
Redux’s ideology is a unidirectional data flow. This pattern reduces long term complexity, encourages re-usability, and generally discourages spaghetti code. 🍝
The core of everything is the Store, Action, and Dispatch. In its simplest form it’s all you technically need. From there Thunks & Sagas enhance the the tooling around the Dispatching of Actions.
Store
A singleton object/state for the app.
Action
A payload describing what data you want to update in the store.
Join me for a story about my journey migrating my personal API server to a new host. Never has there been such thriller as this adventure. There are learnings, distraction, stories, and of course a bitter sweet goodbye.
What do I host with my API server?
It’s a Node.JS express server.
Code is a joy of mine. In my spare time I tend spin up side projects and build experiments. Many of these ideas depend on storing & responding with data, thus I wrote a lightweight NodeJS express server to act as my generic multi-tenant api to server all apps I may rapidly prototype.
Some notable projects include:
DancingQuest – Chicagoland & Wisconsin Social Dance Calendar
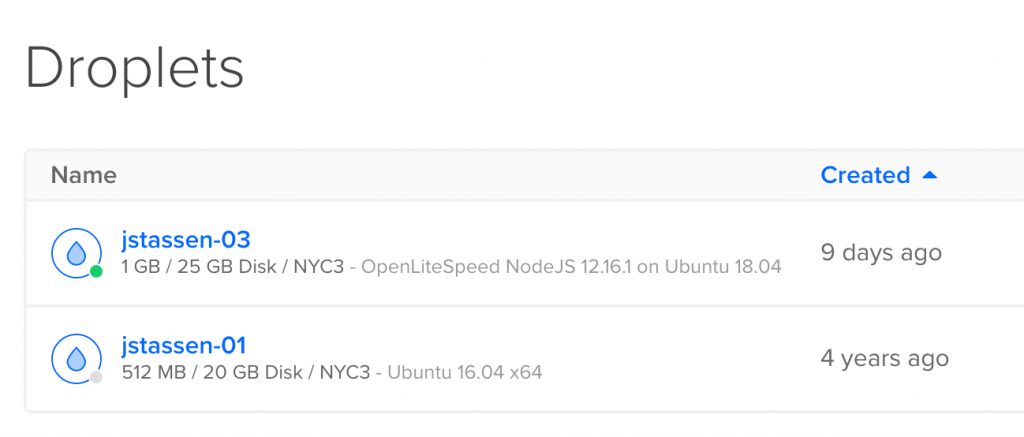
1) I use DigitalOcean as my host. The server cost $5/mo. I created the box 4yrs ago. For new boxes DigitalOcean now offers more RAM & Hard Drive space at the $5 tier.
What happened to jstassen-02? RIP
2 ) Ubuntu upgrade form 16.04 to 18.04. I could just upgrade the system, but value in starting fresh right?
3) Ok ok, dpkg is also very broken on jstassen-01, something with the python 3.5 package being in a very bad inconsistent state. I would really like install docker and start running mysql or mongo db. I started to fix dpkg to get this working, but that went down a rabbit hole.
Given these 3 nudges, it just made sense to swap to a new box, install node and call it a day.
I got distracted at LiteSpeed!
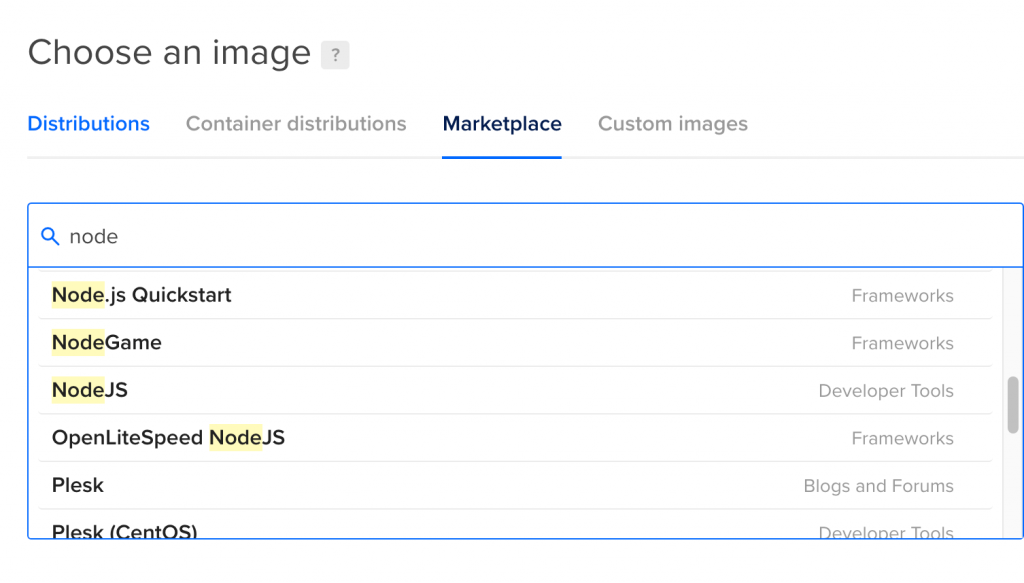
I used DigitialOcean’s pre-configured Node boxes to get me started instead of going from a bare Ubuntu box this time. They have some nice ssh security & software firewalls prebuilt. Wait, but what are these other options?
Ooo what’s this? OpenLiteSpeed NodeJS? Never heard of it, let’s try it out!
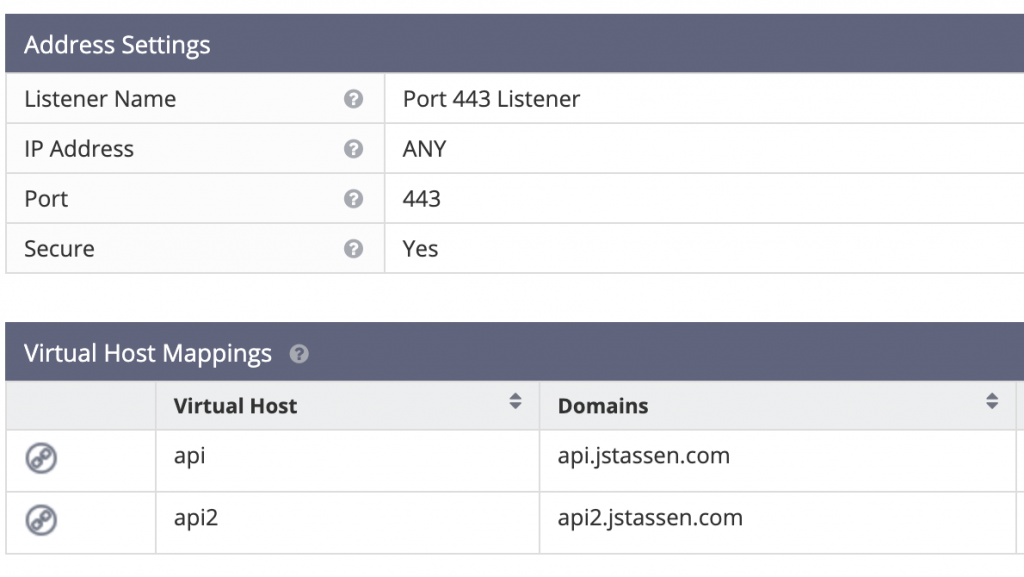
After much confusion and configuration (C&C) I had things running pretty well. It required some modifications to the node app. The benefit of running the Reverse Proxy, the box can now listen on port 445 (https) and based off the domain name route to separate apps in the future. Do I need this? Not really, but don’t mind the option.
OpenLiteSpeed Listener configuration & Virtual host mapping page. This will be handy.
Then the code changes started
OpenLiteSpeed integrates & uses Let’s Encrypt out of the box. Previously I had the Node app handling serving up the certs. It’s rather nice to have the Node app be responsible for less. This brings the dev and production app closer together in parody.
The Database files are document based dbs stored to disk in flat files. It was nice to better organize where these were located on my file system. The migration to a docker based mysql or mongo db is a separate project. (whew avoided one distraction)
A new home
Next was updating the url to a more generic one. I previously used https://jstassen-01.jstassen.com. I could simply point that url at the new box. But that’s kinda ugly jstasssen-01 points to a server named jstassen-03 right? Hm. What about create a url like https://api.jstassen.com then it won’t matter what box it points to in the future.
Fun fact, API calls from an app won’t follow 301 redirects. So, redirecting jstassen-01.jstassen.com -> api.jstassen.com won’t work, especially with POST requests. Well Bummer.
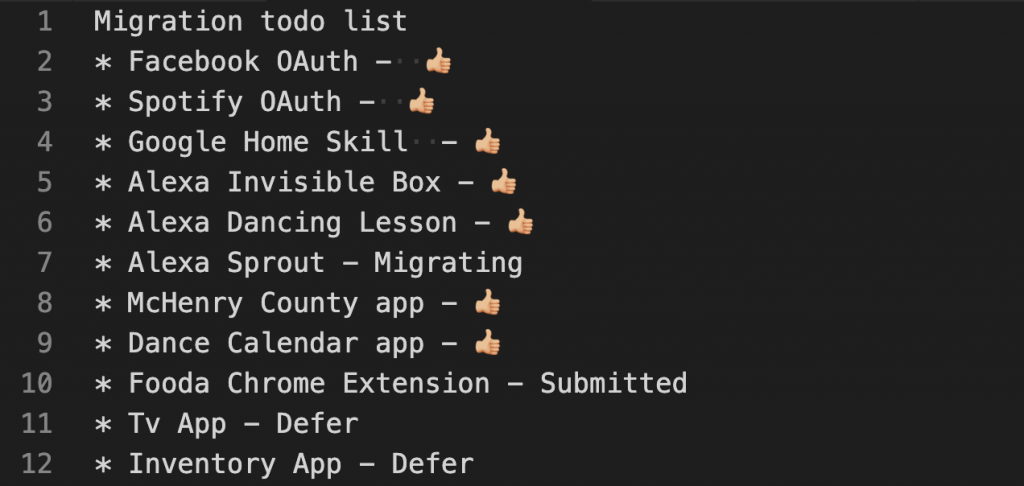
No worries I can update all my apps to use to a new url. No big deal! … oh right that’s 11 different projects. Hm.
Tracking my progress. Emojis always help.
Half were very easy, however I wrote my first google chrome extension and Alexa skill back 4 years ago. I last updated & published them about 1 year ago. A lot of security changes have been updated for how these apps are now built. They have refined their permissions, coding patterns, and apis.Previously grandfathered in as legacy for both, but to redeploy, I needed to upgrade them. Sure, that can’t take long.
Next I noticed OAuth apps were failing. Cookies were failing to be set entirely. Kinda critical piece to remembering which user is authenticated! Interestingly Express.js by default won’t trust credentials forward to it through a reverse proxy (like LiteSpeed). Just needed to allow 1 layer of proxied requests. app.set('trust proxy', 1). Well that one liner took an evening to figure out, haha.
You mean I have to rebuild?
To use use the newest packages, I needed refactor both the google chrome extension and Alexa skills. 1 week later, whew it was complete! On the upside, all my dependencies are fresh and up to date. I now have a modern promise based ajax library and promise based db read / writes. Fancy.
I swear all I wanted to do was copy the code over to a new server and start it up. I didn’t bargain for these code improvements and refactoring.
Performance Testing
Is it faster? I ran 1,000 requests 10 concurrent against a heavy GET endpoint. The new box is on par and just marginally faster ( maybe 1%?) but it’s insignificant difference. Reasure none the less.
RIP jstassen-02, you were taken from us much too soon.
jstassen-02 (RIP) was a failed experiment running Plesk server. It was heavy, a RAM hog and just not optimized. Not to mention Plesk limits your vhosts. Api calls sometimes took twice as long compared to jstassen-01.
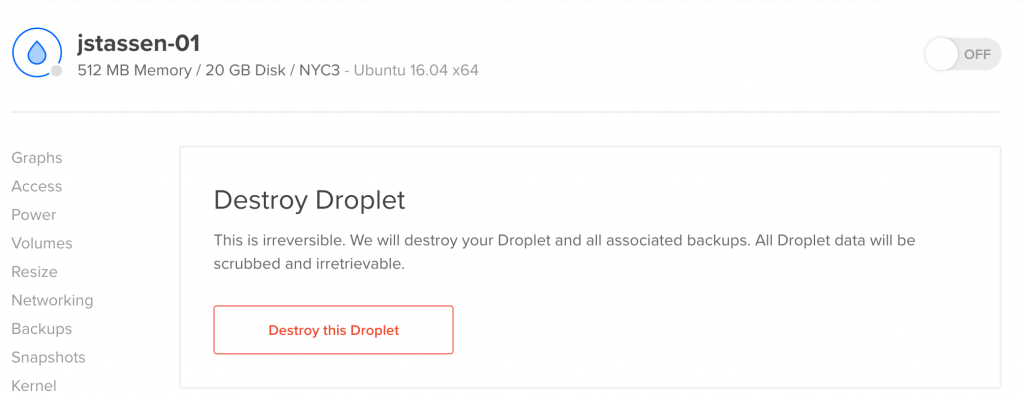
Backing up
It’s time to say farewell and delete jstassen-01. I’m not scared at all, why would I be? And yet I hesitate.
I found this youtube video with a reasonable way to create an archive of the Ubuntu box I can hold on to just in case. Can I restore from it? Hard to say. But at least the data will be there in the off chance I missed something.
# Backup
sudo tar -cvpzf jstassen-01.tar.gz --exclude=/backup/jstassen-01.tar.gz --one-file-system
# Restore
sudo tar -xvpzf /path/to/jstassen-01.tar.gz -C /directory/to/restore/to --numeric-owner
A small 3.24GB archive. I could make the archive smaller by clearing npm/yarn cache folders and clear temp files. But it’s close enough, not too bad.
Maybe next I’ll experiment with creating a new Droplet for a day (a droplet for a day probably cost something like $0.17) and try a restore. Would be interesting to understand this style of backup.
This probably was a bit overkill since I’ve also started to create 1 off private repos on GitHub and use them as a backups as well. So I a committed version my whole home directory too.
Using .get() then .set() seems simple and clean, but it’s slow, it fully replaced the the current Map. While the results are the same, ImmutableJS cannot optimize against it and cannot make some faster assumptions.
It is much better to using Immutable.js .update(). Immutable can keep more references and make assumptions that allow it to optimize the update. For more, check the .update() docs.
You can also use .updateIn() for deeply nested data. Read my post on Immutable get() vs .getIn() to see how it works.
When comparing Immutable.Set() and Immutable.OrderedSet() you’ll need to convert the OderedSet down to just a plain Set.
Comparing Immutable.Set() and Immutable.OrderedSet()
To compare equality with a Set and OrderedSet use this:
mySet.equals( myOrderedSet.toSet() )
Immutable .equals() compares the left and right to decide if they are both Ordered. If one is ordered and the other is not, they are not equal. isOrdered(a) !== isOrdered(b).
My Feelings
I find this a bit odd, especially when the left is a plain Set. I feel regardless if the right is Ordered or not, it’s the contents that we’re interested in comparing. However this is the Immutable.js definition. You will need to downgraded the OrderedSet for comparison via .toSet() which does have a slight cost to it. Immutable performance is worth keeping an eye on.
When selecting state out of our store we’ve written a collection of selectors to consolidate selectors logic. We’ve always write these selectors in array notation to keep styles consistent.
messageStore.getIn([id, 'author', 'screenname']);
With all selectors written in array notation, for Immutable.js we use .getIn() by default — regardless if the path is only one key deep. It’s very convenient. Keeps our selectors looking consistent in shape.
messageStore.getIn([id]);
Immutable.js .get() vs. .getIn()
However it is always faster to do a .get() instead of a .getIn() . For .getIn() Immutable.js has to iterate through an array path and check the result for each key path along the way. This therefore makes .getIn() expensive and .get() ultimately cheaper.
Abstract .getIn()
So if we wish to keep all selectors a consistent array path style, but take advantage of the speed of.get() whenever possible we could make a get abstraction. The first thing to do is to create an abstraction for Immutable .getIn() — something like this:
Add .get() to the abstraction.
How could we get this handy abstraction to take advantage of .get() whenever possible?
We could peak into the arrayPath , if there is only one value, use plain old .get(). Seems simple enough.
But is it performant?
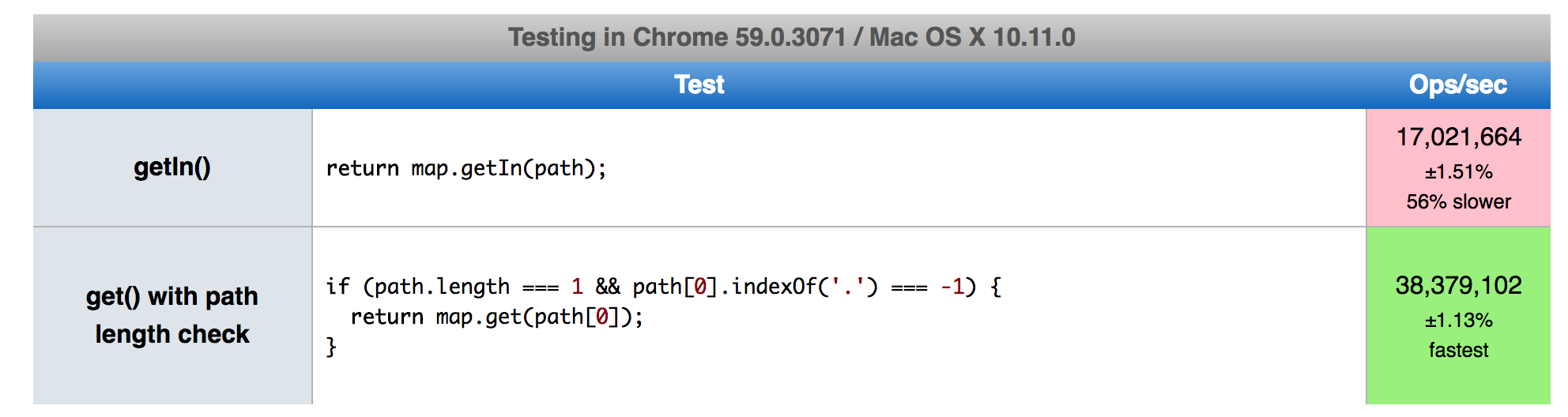
Array length checking is cheap. With a quick little JSPerf test we can see immediately takins the time to check if we should use .get() is more than twice as fast than just always using .getIn().
In the end, this is a micro optimization. However, we saw ~50ms to ~150ms speedups for every actions in the app. It really depends on the how often your selectors run. We have a large number of selectors that fire quite a bit. For such a small change, we’ll gladly take any performance boost over 100ms.
Don’t worry about the abstraction, just remember to prefer.get() over .getIn() whenever possible.
Pro tip: Same goes for .set() / .setIn() and .update() / .updateIn(), etc.
Here are a few mixins I’ve created for LoDash.js I’ve found handy.
_.getDeep
/**
* Safely retrieves the value of a deeply nested object value
* @param {object} O The Object to be searched
* @param {string} str Dot notation string of the address of the attribute to be retrieved
* @return {mixed} Value of nested item or undefined
* @link http://stackoverflow.com/a/15400575/417822
*/
_.mixin({'getDeep': function(O, str) {
if ( !_.isObject(O) ) return;
var seg= str.split('.');
while(O && seg.length) {
O = O[seg.shift()];
}
return O;
}});
/**
* Tests if a deep value has a value/exists. Uses _.getDeep to retrieve value.
* @param {object} O The Object to be tested
* @param {string} str Dot notation string of the address of the attributed to be tested
* @return {boolean}
* @todo validate that falesy values 'false' '0' etc come back as true.
*/
_.mixin({'hasDeep': function(O, str) {
return !_.isUndefined( _.getDeep(O, str) );
}});
_.isDefined
Because typing !_.isUndefined() all the time is tiresome. Using _.isDefined is clear and more readable.
/**
* Shorthand for !_.isUndefined
* @param {mixed} e Item to be tested
* @return {boolean}
*/
_.mixin({'isDefined': function(e) {
return !_.isUndefined(e);
}});
/**
* Removes all falsy and undefined values from an object
* @param {object} o Object to be compacted
* @return {object} Compact Object
* @link http://stackoverflow.com/a/14058408/417822
*/
_.mixin({'compactObject': function(o) {
var clone = _.clone(o);
In my understanding there are different types of data. Each is unique in purpose, mutability, and scope. Clearly identifying the role of an attribute and grouping it with related ones creates a cleaner interface to work with.
Raw Attributes
The raw data that is persisted to the server.
This data should be treated as if immutable, unless planning to persist a change of one of the values to the database. This is the once source of ‘truth’ that is trustworthy. If it is reformatted, or changed it looses its trustworthiness.
More often than not these are a convince to remove the need to repeat logic throughout the app.
If there is an urge to create a value here to describe the model’s content ‘isAdmin’, ‘fullName’, there is a good chance these ought to be part of the data schema to start with.
They can come at a cost of being computed but not always needed everywhere throughout the app. Alternately getter functions could be used to allow a more ‘on-demand’ approach (add result caching and get the both of both worlds).
Describing the state status, of either the data or of the component/view.
State data describes progress or what things are doing currently – [changing, updating, modified]. While these are similar to configuration items, they mutable are more closely tied to the model data describing what is happening to it. If their were multiple components/views that display the same model, they may all want to know the current state of the data. It’s meta data to the data.
These ought be on the component/view that is rendering the item. It describes the preferences of how something should behave or be displayed. Think of them as options, ways to deviate from the norm, an API for this component/view.
A component/view should have a set of defaults for these values to fall back upon.
Config attributes can make it tempting to overload abstraction. Draw a line of making a new component/view when the core functionality has config options that cause different logic paths.
It can be very tempting to merge or stuff configuration and state data right into the model data. It’s convenient, but lazy. It taints the raw data. If put an ‘isLoading’: true value into our data model then persist it to the server, we ought to feel like we did something wrong.
Ideally we would be able to group data in our actual data structures, but at minimum, we can always just keep in mind the role of an attribute and group mentally.
TL;DR
Not all data is alike.
Don’t mutate / override original data
Computed, State, and Config data shouldn’t be mixed in with raw data.